Des motifs universels émergent dans 22 langues et révèlent l’évolution des vocabulaires
Auteur: Mathieu Gagnon/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F04%2Fimage-2026-04-27T10-16-18-021Z.png)
Le reflet de nos sociétés à travers les mots
Les langues humaines connaissent des transformations majeures tout au long de l’histoire. Ces évolutions constantes reflètent intimement les changements technologiques, culturels et sociétaux des différentes époques. L’étude approfondie de ce développement linguistique offre un aperçu précieux sur la manière dont les sociétés humaines et leurs cultures se sont métamorphosées au fil du temps.
La journaliste Ingrid Fadelli a rapporté sur le site Phys.org les travaux d’une équipe de chercheurs issus des universités de Fudan, d’Harvard et de Stony Brook. Ces experts ont récemment exploré l’évolution de vingt-deux langues différentes. Pour mener à bien cette entreprise, ils ont mobilisé une vaste réserve de données linguistiques réelles, combinées à des méthodes statistiques avancées et à des outils d’intelligence artificielle.
L’intelligence artificielle au service des mathématiques

Les conclusions de cette recherche, publiées dans la revue scientifique Proceedings of the Royal Society B Biological Sciences, mettent en évidence une structure statistique commune aux vingt-deux idiomes examinés, ainsi que les schémas qui sous-tendent leur évolution. Steven Skiena, l’auteur principal de l’article, explique la genèse du projet : « De nouveaux mots, concepts et idées sont générés en permanence, mais existe-t-il des modèles cachés qui régissent quels concepts sont susceptibles d’émerger ? Y a-t-il des modèles mathématiques simples qui émulent ce processus ? »
Pour répondre à cette interrogation, les scientifiques ont eu recours au traitement du langage naturel, couramment désigné par l’acronyme anglais NLP. Il s’agit d’algorithmes spécifiquement conçus pour analyser des textes ou de la parole. Steven Skiena précise : « Nous avons été inspirés par l’idée que les technologies d’apprentissage automatique pour représenter la sémantique du langage (les plongements de mots) nous donnent un moyen rigoureux de raisonner sur le matériel complexe fourni par le langage humain. » Ces plongements de mots, ou représentations numériques, relient chaque mot du vocabulaire à un point spécifique dans un espace sémantique en haute dimension, où les termes ayant des significations similaires se retrouvent à proximité les uns des autres.
Une immersion historique dans les données linguistiques

Le professeur Steven Skiena détaille la démarche scientifique adoptée par son équipe : « Par essence, notre article demande comment le vocabulaire de différentes langues est distribué dans cet espace de caractéristiques, et quel type de processus mathématique créerait une distribution similaire ». Ce projet de grande envergure représente un investissement sur le très long terme pour les chercheurs impliqués. L’auteur principal ajoute à ce propos : « Notre article a eu une gestation étonnamment longue : nous travaillons ensemble sur ce sujet depuis plus de sept ans à ce stade, et c’est formidable de voir où nous sommes finalement arrivés. »
Les équipes de recherche ont exploité de vastes ensembles de données contenant des mots en anglais ainsi que dans vingt-et-une autres langues. En convertissant ces termes sous forme mathématique, ils ont pu cartographier leur signification et chercher des récurrences dans leurs relations mutuelles. Sergiy Verstyuk, co-premier auteur de la publication, décrit la méthodologie employée : « Nous avons combiné des données linguistiques remontant jusqu’au Moyen Âge et des outils assez établis, tels que des méthodes de statistiques spatiales populaires en géographie quantitative et en sciences de l’environnement, avec les techniques très modernes d’apprentissage automatique et de traitement du langage naturel. » Il souligne l’importance des résultats obtenus : « Cela nous a permis de découvrir certains faits sur la culture qui se sont avérés vrais pour de nombreuses langues humaines différentes aujourd’hui et tout au long de notre histoire. »
La loi de Taylor et les schémas universels

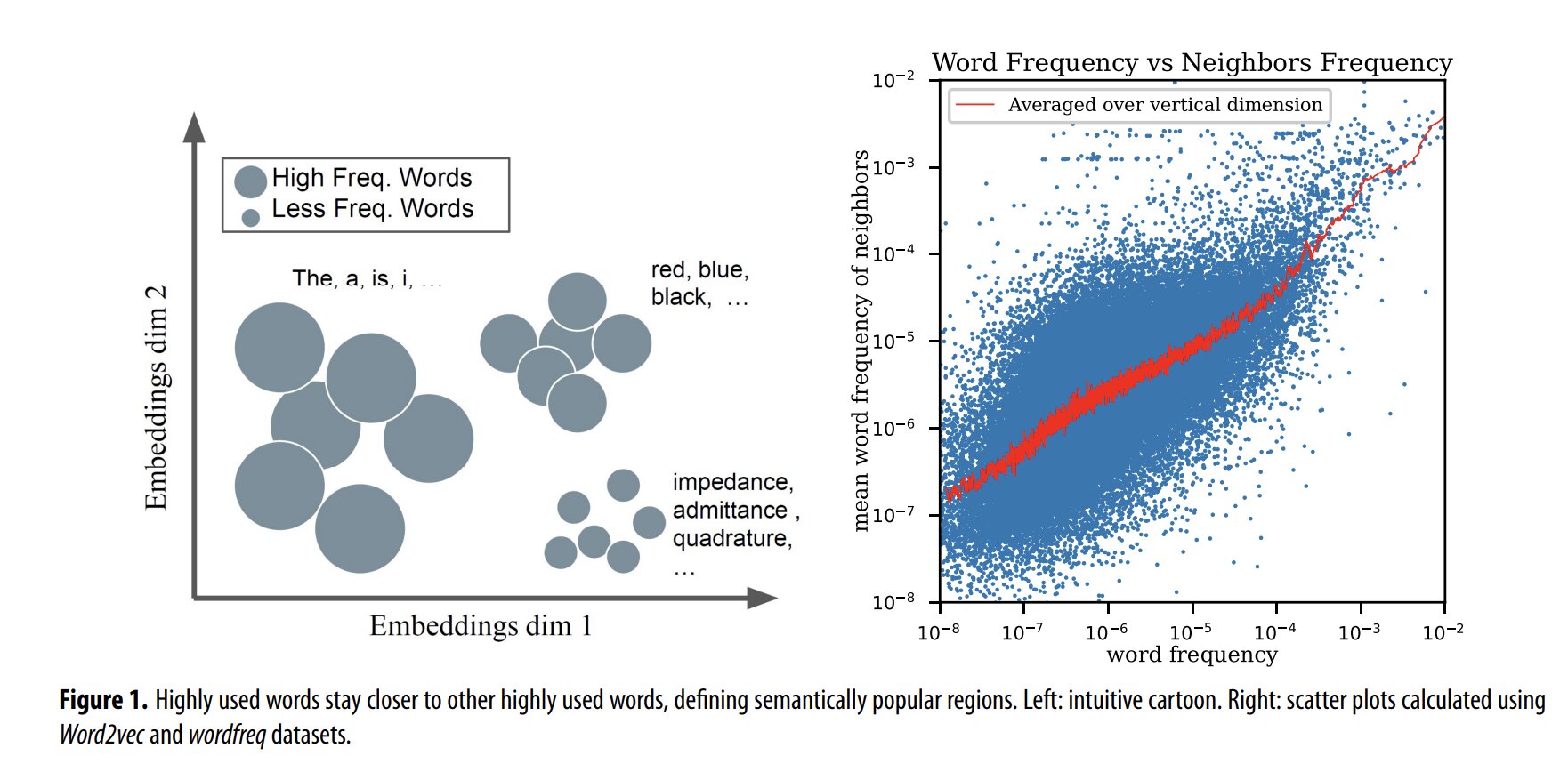
Les travaux conjoints de Steven Skiena, Sergiy Verstyuk et de leurs confrères ont révélé que les vingt-deux langues analysées partageaient systématiquement des schémas universels. En premier lieu, ils ont constaté que les mots populaires se regroupaient de manière constante avec d’autres mots populaires, formant ainsi des régions de mots à haute fréquence. Les chercheurs ont également identifié des profils communs concernant la vitesse à laquelle les mots se regroupent. En d’autres termes, le vocabulaire s’organise selon un modèle hiérarchique dont la structure reste globalement identique à travers toutes les langues étudiées. Le professeur Skiena partage une autre observation frappante : « Nous avons également observé une dynamique temporelle intéressante, montrant que les nouveaux mots sont généralement créés par vagues avec d’autres mots récents autour d’eux ». Cette mécanique rappelle la façon dont l’évolution biologique se déroule, ponctuée par des périodes rapides de changements génétiques ou morphologiques importants.
Par ailleurs, l’étude démontre qu’une règle connue sous le nom de loi de Taylor s’applique aux mots de vocabulaire. Cette loi, initialement découverte pour les communautés écologiques et repérée par la suite dans d’autres échantillons biologiques, des données physiques et des objets mathématiques, se traduit ici par une relation mathématique de type loi de puissance. Elle relie la moyenne et la variance du nombre de mots, classés selon leur sens sémantique et leur apparition historique. Cette découverte offre la possibilité de comprendre simultanément la sémantique et l’évolution du langage humain.
Vers une modélisation du développement culturel

Cette vaste enquête scientifique ouvre de nouvelles perspectives sur l’évolution des langues au cours des siècles passés et sur leurs multiples similitudes. Les schémas statistiques découverts pourraient permettre une compréhension plus rigoureuse des langues humaines. Fait notable, certaines preuves indiquent que d’autres domaines de la culture humaine présentent des modèles similaires. L’analyse des chercheurs a abouti à l’identification d’un processus mathématique stochastique générant des ensembles de mots aux propriétés semblables, ce qui pourrait expliquer en partie la mécanique par laquelle les langues ont été créées et se sont développées dans le temps. Sergiy Verstyuk apporte des précisions techniques : « Nous avons construit un modèle étonnamment simple qui non seulement reproduit les résultats antérieurs sur la distribution en loi de puissance des fréquences de mots (c’est-à-dire se manifestant dans une seule dimension), mais qui rend compte également des nouvelles découvertes empiriques à travers de nombreuses dimensions supplémentaires (spécifiquement, dans l’espace sémantique à 300 dimensions et dans le temps historique). » Il complète son explication : « Cela a été réalisé en mariant un processus d’avantage cumulatif bien connu avec une distribution de probabilité de von Mises-Fisher rarement utilisée. »
À l’avenir, ces travaux inédits pourraient inspirer de nouvelles recherches en linguistique et en anthropologie, mobilisant les mêmes outils modernes. Steven Skiena conclut sur l’ambition de l’équipe : « Nous restons enthousiastes quant aux possibilités d’utiliser les plongements générés par l’IA comme un outil pour la recherche fondamentale dans la compréhension des processus historiques dans l’évolution culturelle — pas seulement pour construire des outils technologiques. » Les détails supplémentaires de cette étude, menée par Xingzhi Guo et son équipe et intitulée « Statistical structure and the evolution of languages », figurent dans le numéro de l’année 2026 de la revue Proceedings of the Royal Society B Biological Sciences, sous l’identifiant DOI: 10.1098/rspb.2025.2374.
Selon la source : phys.org
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-17T11-02-56-007Z.jpeg)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-17T10-56-05-658Z.jpeg)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-17T10-52-53-252Z.png)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-17T10-51-21-354Z.png)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-16T10-03-49-758Z.png)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-16T10-02-44-438Z.jpeg)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-16T09-56-55-439Z.png)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-16T09-51-56-141Z.png)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-16T09-48-23-600Z.jpeg)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-15T10-25-44-848Z.jpeg)
/https%3A%2F%2Flanature.ca%2Fapp%2Fuploads%2F2026%2F06%2Fimage-2026-06-13T10-56-53-830Z.png)